

众所周知,国内短视频团队都雇佣了大量的审核人员,原因是机器对于视频内容的理解大部分只能通过将视频切成一张张的图片,同时将语音转化成文字进行分析和打标签,但即使这样,针对富有“内涵”的视频,机器依然需要审核人员进行帮助。而这一状况或许将随着跟多新技术的应用,逐渐得到解决。
近日,腾讯微视BLENDer单模型凭借“81.6,86.4,70.8”的成绩,一举超过百度、谷歌、Facebook等知名机构的多模型提交结果,登上了多模态领域权威榜单 VCR (视觉常识推理Visual Commonsense Reasoning)。
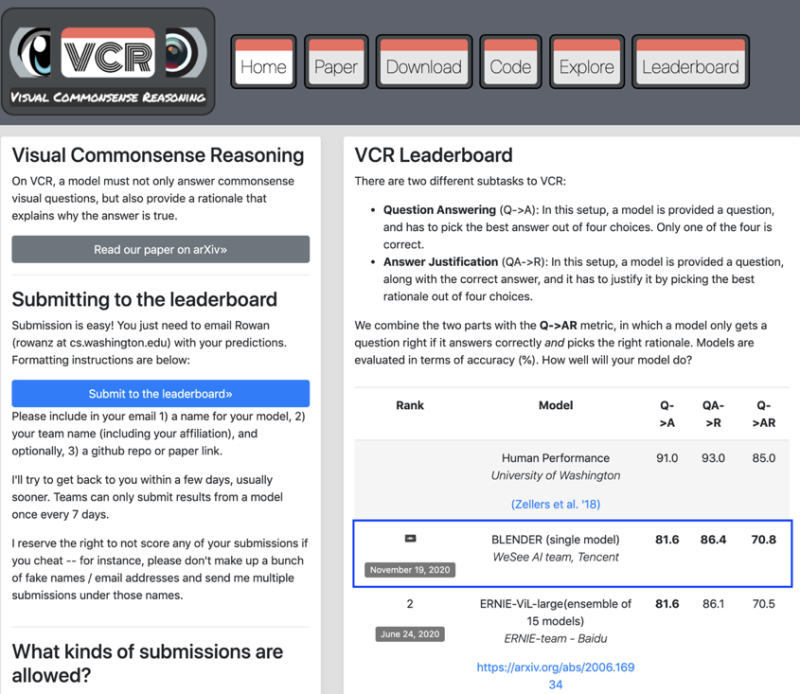
微视相关负责人告诉新京报贝壳财经记者,上述模型的应用,可以使包含文本、音频、视频等信息在内的短视频内容,得到更好地分类和识别。据介绍,BLENDer研发时间不到3个月。
该人士还表示,未来将在机器学习、视频理解等方面投入更多研发精力;另一方面要快速扩充团队和招募人才;内容方面在影视综、游戏等品类上也有积累,并计划发力短剧。
如何让机器读懂短视频“内容”?
既然是短视频业务,就会涉及到内容审核、内容推荐等,视觉常识推理(VCR)解决的就是让机器读懂短视频内容的问题。
2018年,来自华盛顿大学和艾伦人工智能研究所的四位学者联合发起了VCR 任务,该数据集包括 11 万个电影场景中的 29 万个多项式选择题,旨在将图像和识别自然语言理解相结合,让机器拥有“读懂内容”的能力, 例如VCR能够通过图片中人物的行为,进一步推理出其动机、情绪等。
在传统的视觉问答任务中,主要针对的是识别问题,比如图片中的花朵是什么,图片中有几只狗等。但VCR任务的目标则是解决认知层面的问题,比如图片中的人物4为什么指向人物1,在机器做出选择后,还要让机器进一步解释做出上述判断的依据。
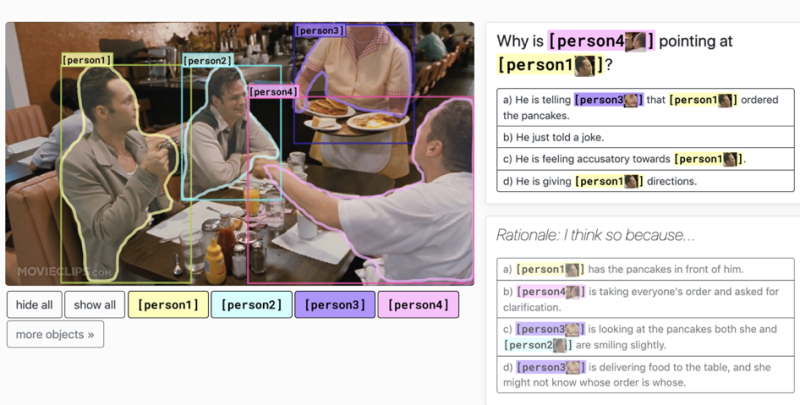
也正因为如此,VCR榜单是多模态理解领域最权威的排行榜之一,也是当前图像理解和多模态领域层次最深、门槛最高的任务之一。
与其他团队采取的是多个模型不同,微视团队采取的是单个模型。据上述微视负责人介绍,BLENDer模型的处理速度和大小都相对优秀:在运算速度方面,每秒钟可以推理50张至60张图片;模型的大小约为1.3G,只相当于其他团队多融合模型中的单个模型。
上述微视负责人介绍称,该模型第一阶段以NLP中的Bert模型为起点,结合海量数据中抽取得到的数百万张图片和描述文本作为BLENDer的输入进行多模态训练;第二阶段,在视觉常识推理数据集上学习电影中的场景和情节,使模型在新数据上获得更好的迁移能力;第三阶段,引入最终问答任务,让BLENDer利用已有的知识和常识对现有问题进行“人物-人物”、“人物-场景”之间关系的挖掘和关联进行推理,得到最终的答案。
上述负责人还透露,目前团队还在对模型进行优化,是为了日后更好地将模型应用到业务中。而BLENDer模型,还不是该团队的最优模型。
微视的新目标
作为腾讯在短视频赛道的重要产品,微视过去一年做了哪些工作?未来又将如何发力?
“短视频是内容行业未来重要的发展方向,它正在跟过往的内容形式,如图文、长视频结合,进而让用户产生新的内容消费习惯。”上述微视负责人介绍了其对短视频行业的判断,在他看来,对微视而言,未来如何能够提升用户的信息获取效率,会是重点发力的方向。这就包括短视频的理解、分发、推荐以及内容质量、运营联动等方面。
近期任务,是抓住春节的机会,提升用户增长和用户对微视的认知,具体的数字化目标是用户日活和用户时长。内容方面,影视综、游戏和微视短剧会成为重点发力方向。
在此前一年,微视更多的工作是“打牢基础设施”。在技术方面,腾讯微视将3D人脸、人体、AR(增强现实)技术等技术结合,辅助用户进行内容创作,让创作过程更加便捷, 同时用图像检测、分类等技术提升审核效率。内容方面,引入很多PGC(专业内容生产)和UGC(用户内容生产)的创作者,此外微视还与文学、动漫、游戏、音乐、影视等团队实现联动,提升了IP运营效率。
据腾讯控股2019年第四季度财报,微视的日活跃用户数环比增长80%,日均视频上传量环比增长70%。而根据QuestMobile《中国移动互联网2019半年大报告》,截至2019年6月,微视的月活用户已经突破1亿。
这个成绩对2018年才上线,在短视频头部玩家已经固定的环境下生长的微视,是可圈可点的。但横向来看,快手、抖音已在今年年中先后宣布日活突破3亿和6亿。可以说,一切对于微视而言,任重道远。
新京报贝壳财经记者 白金蕾 编辑 徐超 校对 陈荻雁











