

从参数竞赛到智能密度:一条人迹罕至的路
在通往AGI的道路上,大模型产业长期被两种主流叙事所主导:一是以参数规模为核心的“军备竞赛”,二是以API调用和Agent为核心的商业化肉搏。然而,面壁智能却开辟了第三条道路:一条以“智能密度”为核心的精益化突围之路。如何在极度有限的资源下,构建出更高能力的模型成为公司聚焦更为本质的问题。
“密度定律”:大模型领域的摩尔定律
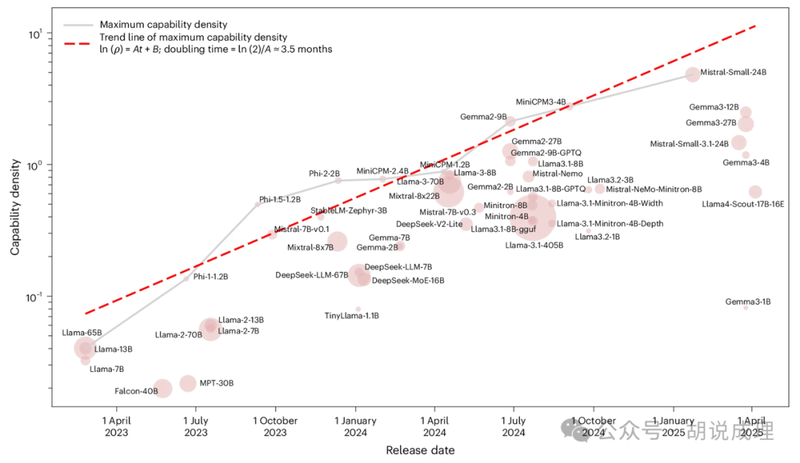
这条独特路线背后的核心理论框架,是面壁智能提出并不断深化的“密度定律”。所谓的大模型密度定律,可以理解为大模型领域的摩尔定律:大模型的智能密度每3.3个月翻一番。智能密度被精确定义为模型能力与推理算力能耗的比值——同等能力的模型,在100多天后仅需约一半的参数就能实现。当行业普遍将参数规模视为能力核心时,面壁智能早已转向了不同的函数:真正决定模型价值的,是单位参数所承载的有效智能。
小钢炮的崛起:用工程奇迹打破“模型迷信”
这一理论在工程层面的兑现,清晰体现在其端侧模型的迭代上。2024年2月,面壁智能推出首个端侧大模型MiniCPM,仅用24亿参数便超越同期百亿参数模型的能力,打响了“小钢炮”的名号。此后,用40亿参数逼近GPT-3.5水平,又用80亿参数直逼GPT-4能力,彻底打破了“模型必须大”的迷信,证明小参数也能具备大智慧。
风洞实验与极简算力:寻找最优解的独特方法论
为了实现这种高效能,面壁智能自研了分布式训练框架BMTrain,仅用几十张显卡便可启动百亿级模型训练,这不仅是对标DeepSpeed或Megatron的工程实现,更是其“密度定律”的体现。正是这种极致工程化追求,让面壁智能的端侧多模态研究成果登上《Nature》子刊,并连续推出MiniCPM-o、MiniCPM-V4.5等开源模型,以不到同行九分之一的参数量,在端侧实现语音、视频、文本的全模态实时同步交互。
向上兼容的技术护城河:从小模型走向大未来
面壁智能选择端侧路线,并非因为端侧是终点。正如其首席研究员韩旭所言,训练端侧模型的过程本身就是寻找大模型方法论的过程。掌握了这套方法论,将参数规模放大、算力加码,也能很快训练出更大模型。这种“向上兼容”的技术积累,正是面壁智能能够持续穿越技术周期、跻身行业前沿的核心壁垒。